Introduction
- initialize a new student and train it with the dual goals of predicting the correct labels and matching the output distribution of the teacher, which leads the students toward better local minima
- call students Born Again Networks (BAN) and show that applied to DenseNet
Method
- based on the empirical finding that the solution \theta_1^*
- self as a teacher to next step
- Sequence of Teaching Selves Born Again Networks Ensemble
-
sequence born

-
ensemble
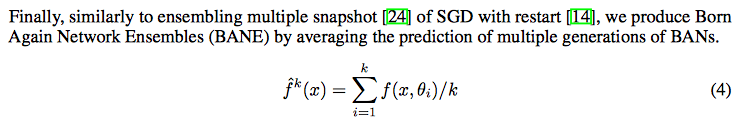
-
Experiments
-
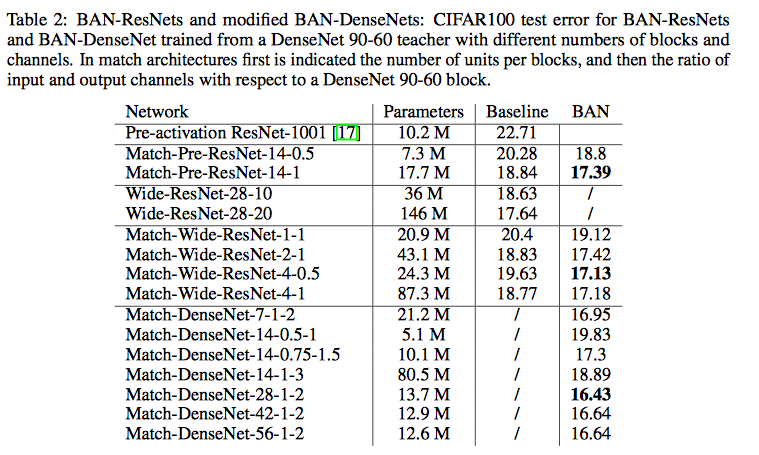
DenseNets Born Again as ResNets
-
Baseline: wide-ResNet and bottleneck-ResNet match the output shape of DenseNet-90-60 at each block
-
BAN-Resnet: the student shares the first and last layer with its teacher (DenseNet 90-60)
-
Result